자전거 타기를 처음 배울 때 넘어지면서 균형 잡는 법을 몸으로 익히듯, 인공지능도 무수한 실패를 통해 스스로 정답을 찾아가는 방법이 있다. 바로 알파고와 자율주행 자동차를 탄생시킨 핵심 기술인 강화학습이다.
기존의 머신러닝이 사람이 미리 다듬어놓은 정답 데이터를 외우는 방식이었다면, 강화학습은 인공지능이 스스로 가상 환경과 부딪치며 얻은 경험 데이터를 가공하여 최적의 행동 전략을 세우는 진일보한 기술이다.
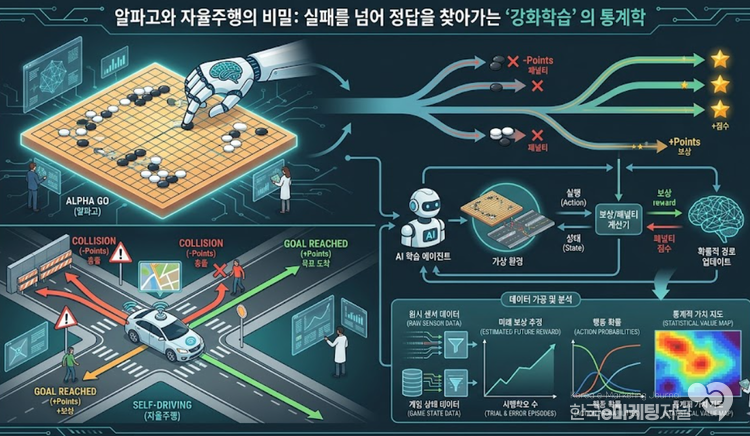
강화학습의 핵심은 보상과 패널티라는 통계적 시스템에 있다. 자율주행 자동차를 예로 들면, 차선 안에 머물거나 목적지에 무사히 도착하면 더하기 점수를 받고, 장애물과 충돌하거나 차선을 벗어나면 빼기 점수를 받도록 알고리즘이 설계된다.
인공지능은 매 순간 카메라와 센서로 수집된 엄청난 양의 시각 데이터를 전처리하여 현재 상태를 수치화하고, 무작위로 행동을 취해본다. 그리고 그 결과로 얻어진 점수들을 수학적으로 계산하여, 미래에 가장 높은 보상을 받을 수 있는 확률적 경로를 스스로 업데이트한다.
이 과정에서 발생하는 수백만 번의 시행착오 데이터는 결코 의미 없는 실패의 기록이 아니다. 인공지능은 이 방대한 오답 데이터를 가공하여 어느 상황에서 어떤 행동이 유리한지를 나타내는 정교한 통계적 가치 지도를 그려낸다.
분석가들이 데이터 시각화를 통해 이 지도를 들여다보면, 처음에는 무질서하게 흩어져 있던 수치들이 무수한 반복을 거치며 점차 하나의 명확한 최적 경로로 수렴해 가는 놀라운 궤적을 확인할 수 있다.
결국 강화학습은 실패라는 거친 원시 데이터를 가공하여 성공이라는 정답으로 바꾸는 고도의 통계적 연금술이다. 주입된 데이터의 한계를 벗어나 스스로 진화하는 이 데이터 가공 기술 덕분에, 컴퓨터는 이제 바둑판의 무한한 경우의 수를 정복하고 복잡한 도심 한복판을 스스로 판단하며 질주할 수 있게 되었다. 경험 데이터가 축적될수록 인공지능이 그리는 미래의 지도는 더욱 정교해질 것이다.
[※ 칼럼의 그림 및 도표는 AI 활용하여 작성됨]








