컴퓨터는 태생적으로 숫자만을 이해하는 기계이다. 하지만 오늘날의 인공지능은 우리가 일상적으로 사용하는 언어인 자연어를 능숙하게 주고받으며 질문에 답하고 글을 쓴다. 딱딱한 기계가 어떻게 인간의 복잡 미묘한 문장을 이해하는 것일까. 그 비밀은 문자를 정교한 수치 데이터로 변환하고 가공하는 자연어 처리 기술에 숨어 있다.
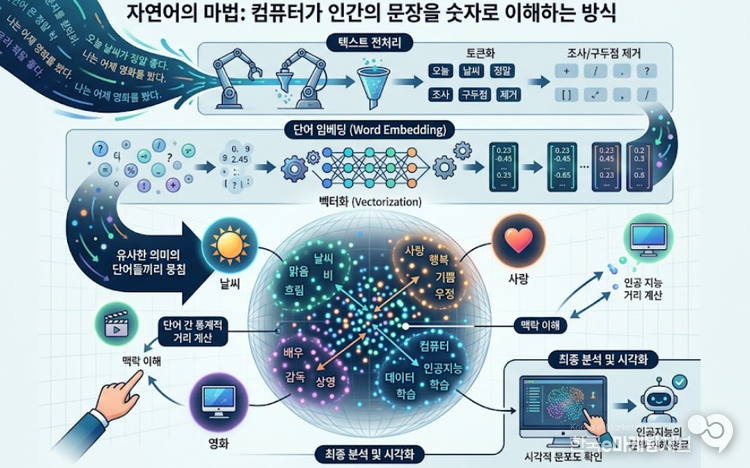
단순히 글자를 입력받는 것을 넘어 의미를 파악하기 위해서는 먼저 텍스트를 정제하는 전처리 과정이 필요하다. 문장에서 의미 없는 조사나 구두점을 제거하고 단어의 뿌리가 되는 어근만을 남기는 토큰화 작업을 거친다.
이렇게 쪼개진 단어들은 숫자로 치환되는데, 과거에는 단순히 순서대로 번호를 매겼다면 현대의 인공지능은 단어를 벡터라고 불리는 수천 차원의 공간상 좌표로 변환한다.
이 가공 방식의 핵심은 비슷한 의미를 가진 단어들을 공간상에서 가깝게 배치하는 통계적 학습에 있다. 예를 들어 왕과 여왕이라는 단어는 공간상에서 비슷한 위치에 놓이게 되며, 이들 사이의 거리와 방향을 계산하면 단어 간의 관계를 수치로 파악할 수 있다. 컴퓨터는 문장을 읽는 것이 아니라 수많은 숫자 좌표들 사이의 거리를 측정하며 문맥을 이해하는 셈이다.
잘 가공된 단어의 좌표값들은 시각화를 통해 그 구조가 명확히 드러난다. 수만 개의 단어가 거대한 구름처럼 모여 있는 분포도에서 비슷한 주제의 단어들이 끼리끼리 뭉쳐 있는 모습은 데이터 분석의 경이로움을 보여준다.
결국 우리가 인공지능과 나누는 대화는 수조 개의 숫자가 정교하게 계산되고 이동하며 만들어낸 통계적 결과물이다. 텍스트를 숫자로 바꾸는 이 마법 같은 가공 기술 덕분에 기계는 인간의 언어라는 거대한 바다를 자유롭게 항해하고 있다.
[※ 칼럼의 그림 및 도표는 AI 활용하여 작성됨]








