우리가 매일 사용하는 이메일함에는 보이지 않는 파수꾼이 살고 있다. 바로 스팸 메일 차단 시스템이다. 광고나 사기성 메일이 수시로 쏟아짐에도 불구하고 우리의 편지함이 비교적 깨끗하게 유지되는 비결은 머신러닝이 데이터를 정교하게 가공하여 숫자로 분류하기 때문이다.
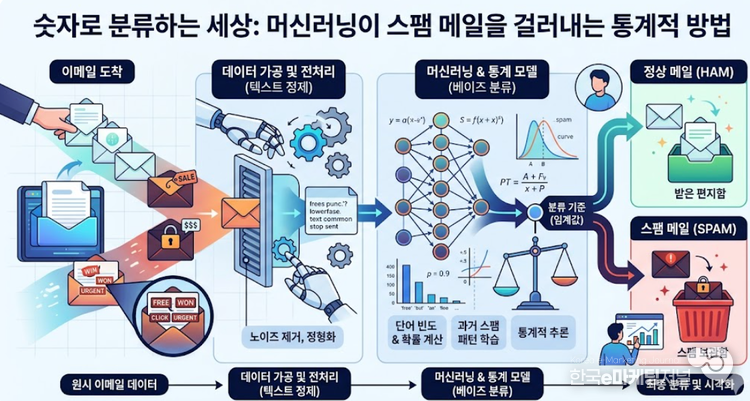
컴퓨터는 이메일의 내용을 읽고 감정을 느끼는 것이 아니라, 텍스트를 통계적 수치로 변환하여 스팸 여부를 판단한다.
스팸 분류의 첫 단계는 텍스트 데이터의 전처리이다. 컴퓨터는 문장 전체를 그대로 이해하기 어렵기 때문에 문장을 단어 단위로 쪼개는 과정을 거친다. 의미 없는 조사나 기호를 제거하고 단어의 원형만을 남기는 정제 과정을 거치면 비로소 분석을 위한 준비가 끝난다. 이렇게 가공된 데이터는 각 단어가 스팸 메일과 정상 메일에 나타날 확률을 계산하는 통계 모델에 입력된다.
여기에 사용되는 대표적인 기법이 베이즈 정리라는 통계적 방법이다. 예를 들어 '무료', '당첨', '광고'와 같은 단어가 포함되었을 때 해당 메일이 스팸일 확률을 과거 데이터를 바탕으로 계산하는 식이다.
머신러닝 모델은 수만 건의 데이터를 학습하며 특정 단어 조합이 나타날 때의 위험 수치를 정밀하게 다듬는다. 단순히 단어 하나만 보는 것이 아니라 단어들 사이의 연관 관계까지 수치화하여 분류의 정확도를 높인다.
최종적으로 가공된 통계 수치는 시각적인 분류 경계선을 만들어낸다. 정상 메일 그룹과 스팸 메일 그룹 사이의 보이지 않는 선을 긋고, 새로 도착한 메일이 어느 영역에 속하는지 숫자로 판별하는 것이다.
우리가 인식하지 못하는 찰나의 순간에 데이터는 가공되고 확률로 계산되어 편지함의 위치를 결정한다. 결국 스팸 차단은 언어를 숫자로 바꾸고 확률로 미래를 예측하는 데이터 사이언스의 정수가 담긴 기술이다.
[※ 칼럼의 그림 및 도표는 AI 활용하여 작성됨]








