어린 시절 즐겨 하던 '스무고개' 게임을 떠올려 보자. "동물입니까?", "다리가 네 개입니까?"와 같은 질문을 거듭하며 정답의 범위를 좁혀나가는 이 영리한 놀이는 머신러닝의 '의사결정 나무(Decision Tree)' 알고리즘과 완벽하게 닿아 있다.
복잡하게 얽혀 있는 원시 데이터 속에서 컴퓨터는 "나이가 30대 이상인가요?", "과거 구매 이력이 있나요?"라는 통계적 기준을 세우고, '예/아니오'의 갈래를 치며 데이터를 분류해 나간다. 그 과정이 직관적이고 최종 결과를 인간이 해석하기 쉬워 데이터 분류의 기초로 널리 쓰인다.
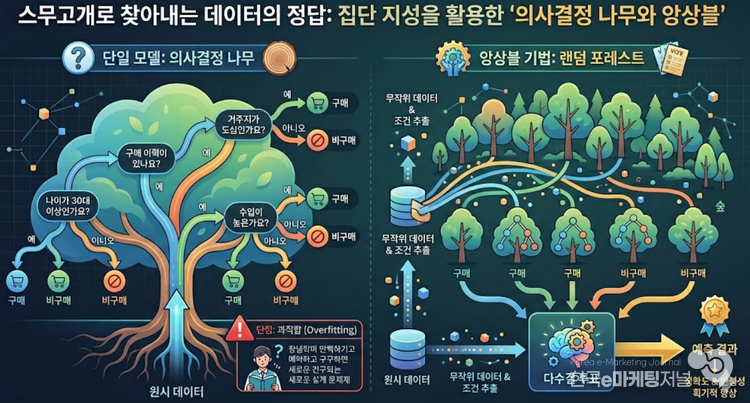
하지만 의사결정 나무라는 단일 모델에는 치명적인 약점이 존재한다. 주어진 학습 데이터에만 맞추어 너무 깊고 뾰족하게 질문을 파고들다 보니, 융통성 없이 데이터를 통째로 외워버리는 '과적합(Overfitting)'의 함정에 빠지기 쉽다는 것이다. 즉, 실험실의 연습 문제에서는 백 점을 맞지만, 막상 변수가 많은 새로운 실전 데이터가 입력되면 엉뚱한 오답을 내놓고 마는 한계를 지닌다.
데이터 과학자들은 이 문제를 극복하기 위해 인간 사회의 '집단 지성' 원리를 데이터 가공에 도입했다. 바로 나무 한 그루에 의존하는 대신 수백, 수천 그루의 나무를 심어 거대한 숲을 이루는 '랜덤 포레스트(Random Forest)'와 같은 앙상블(Ensemble) 기법이다.
이 기술은 전체 데이터에서 무작위로 조금씩 다른 샘플과 조건을 추출하여 수많은 의사결정 나무를 각기 다르게 학습시킨다. 그리고 새로운 문제가 주어지면 모든 나무가 각자의 결론을 내리게 한 뒤, 다수결 투표를 통해 최종 정답을 도출한다.
어떤 나무는 자신이 학습한 편협한 데이터에 치우쳐 잘못된 판단을 내릴 수 있다. 하지만 숲 전체의 다수결을 거치면 이러한 개별적인 오류와 노이즈가 마법처럼 상쇄되며, 놀라울 정도로 정확하고 안정적인 예측이 완성된다.
스무고개를 하는 한 명의 전문가보다, 각기 다른 시각을 가진 백 명의 다수결이 더 진리에 가깝다는 사실. 머신러닝의 앙상블 기법은 차가운 숫자와 통계의 세계에서도 다양성과 집단 지성이 얼마나 강력한 무기가 되는지 보여주는 아름다운 증명이다.
[※ 칼럼의 그림 및 도표는 AI 활용하여 작성됨]








