현대의 데이터 과학자들은 종종 '차원의 저주(Curse of Dimensionality)'라는 벽에 부딪힌다. 예를 들어 한 명의 고객을 분석할 때 나이, 성별, 구매 금액뿐만 아니라 웹사이트 체류 시간, 클릭 횟수, 마우스 궤적 등 수십, 수백 개의 변수(차원)를 수집하게 된다.
하지만 정보가 무작정 많다고 다 좋은 것은 아니다. 분석해야 할 변수가 늘어날수록 오히려 불필요한 노이즈가 섞이고 연산 속도가 느려져 인공지능의 판단을 흐리게 만들기 때문이다.
이토록 복잡한 데이터의 홍수 속에서 가장 중요한 핵심 정보만 압축해서 건져 올리는 통계적 구조대원이 바로 '주성분 분석(PCA, Principal Component Analysis)'이다.
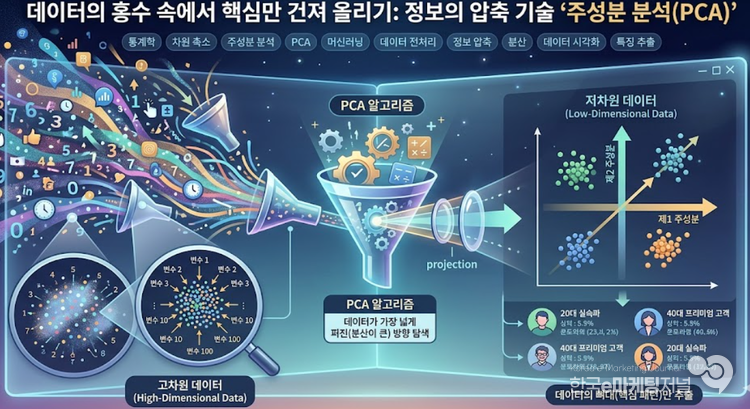
PCA의 원리는 복잡한 3차원의 입체 사물에 빛을 비춰 가장 특징이 잘 드러나는 2차원 그림자를 만들어내는 과정과 비슷하다. 알고리즘은 데이터가 가장 넓게 퍼져 있는(분산이 가장 큰) 방향을 수학적으로 찾아내어 새로운 축으로 삼는데, 이 축이 바로 데이터의 특성을 가장 잘 설명하는 '제1 주성분'이 된다.
이런 방식으로 서로 겹치지 않는 몇 개의 핵심 축을 순차적으로 찾아내면, 100개의 변수로 이루어진 어지러운 데이터도 원래 정보의 80~90%를 보존한 채 단 2~3개의 새로운 변수로 획기적으로 압축할 수 있다.
그 결과, 인간의 인지 능력을 벗어났던 다차원의 복잡한 데이터가 비로소 우리가 눈으로 확인할 수 있는 평면 그래프 위에 명확한 군집이나 패턴으로 그 모습을 드러내게 된다.
결국 주성분 분석은 방대한 숫자의 더미 속에서 군더더기를 과감히 덜어내고 데이터의 진짜 뼈대만 남기는 '통계적 미니멀리즘'이다. 혼돈 속에서 질서를 찾고 정보의 본질을 꿰뚫어 보는 이 우아한 차원 축소 기술 덕분에, 데이터 모델은 한결 가벼워지고 예측은 더욱 예리해진다.
[※ 칼럼의 그림 및 도표는 AI 활용하여 작성됨]








