우리는 매일 일기예보를 확인하고 주식 시장의 흐름을 살피며 내일을 준비한다. 이처럼 시간의 흐름에 따라 기록된 데이터를 시계열 데이터라고 부른다. 단순히 나열된 숫자 더미처럼 보이지만, 그 속에는 일정한 규칙과 반복되는 패턴이 숨어 있다. 데이터 사이언티스트들은 이 복잡한 숫자들 사이에서 의미 있는 신호를 찾아내 미래를 예측하는 지도를 그려낸다.
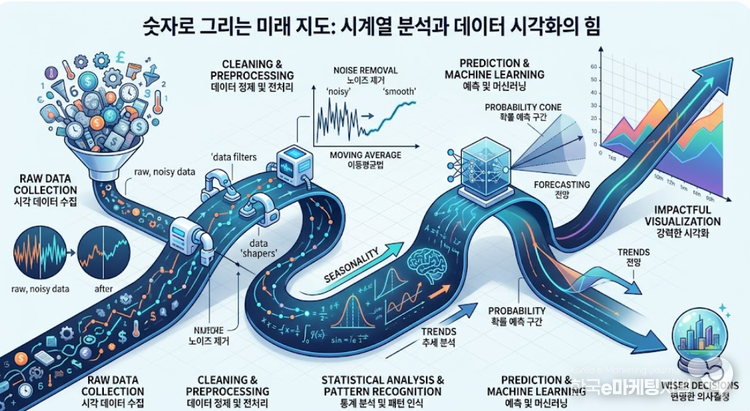
시계열 분석의 핵심은 먼저 데이터를 깨끗하게 가공하는 전처리 과정에 있다. 수집된 원본 데이터에는 측정 오류나 일시적인 소음과 같은 노이즈가 섞여 있기 마련이다. 이동평균법과 같은 통계적 방법을 활용해 들쭉날쭉한 수치를 매끄럽게 다듬으면 데이터가 가진 본래의 흐름이 드러난다.
여기에 계절성 수치를 고려하면 명절에 교통량이 급증하거나 여름에 빙과류 판매량이 늘어나는 것과 같은 주기적인 특성까지 파악할 수 있게 된다.
이렇게 가공된 데이터는 머신러닝 알고리즘을 만나 더욱 강력해진다. 과거의 수많은 패턴을 학습한 모델은 현재의 위치를 파악하고 앞으로 일어날 변화를 확률적으로 제시한다. 하지만 아무리 정교한 수식과 알고리즘이 동원되어도 그 결과를 숫자로만 나열한다면 대중이 이해하기 어렵다. 여기서 데이터 시각화의 진가가 발휘된다.
잘 설계된 시각화는 복잡한 통계 수치를 한 장의 그림으로 압축한다. 가로축에 시간의 흐름을 두고 세로축에 변화량을 표시한 꺾은선 그래프는 직관적으로 미래의 상승과 하락을 보여준다. 색상의 대비를 통해 위기 구간을 표시하거나 추세선을 그려 넣어 전체적인 방향성을 제시하는 방식은 단순한 정보 전달을 넘어 설득력을 갖는다. 결국 데이터 가공과 시각화는 보이지 않는 미래를 누구나 이해할 수 있는 언어로 번역하는 과정인 셈이다.
숫자로 그려진 이 미래 지도는 완벽한 예언서는 아니다. 하지만 불확실한 세상을 항해하는 우리에게 가장 믿음직한 나침반이 되어준다는 점은 분명하다. 데이터를 정교하게 다듬고 시각적으로 표현하는 기술이 발전할수록 우리는 더 현명한 내일을 설계할 수 있게 될 것이다.
[※ 칼럼의 그림 및 도표는 AI 활용하여 작성됨]








